LOD 表达式在数据分析领域很常用,其全称为 Level Of Detail,即详细级别。
精读
什么是详细级别,为什么需要 LOD?你一定会有这个问题,我们来一步步解答。
什么是详细级别
可以尝试这么发问:你这个数据有多详细?
得到的回答可能是:
- 数据是汇总的,抱歉看不到细节,不过如果您正好要看总销量的话,这儿都给您汇总好了。。
- 详细?这直接就是原始表数据,30 亿条,这够详细了吧?如果觉得还不够详细,那只好把业务过程再拆分一下重新埋点了。
详细程度越高,数据量越大,详细程度越低,数据就越少,就越是汇总的数据。
人很难在详细程度很高的 30 亿条记录里看到有价值的信息,所以数据分析的过程也可以看作是 对数据汇总计算的过程,这背后数据详细程度在逐渐降低。
BI 工具的详细级别
如果没有 LOD 表达式,一个 BI 查询的详细程度是完全固定的:
- 如果表格拖入度量,没有维度,那就是最高详细级别,因为最终只会汇总出一条记录。
- 如果折线图拖入维度,那结果就是根据这个维度内分别聚合度量,数据更详细了,详细粒度为当前维度,比如日期。
如果我们要更详细的数据,就需要在维度上拖入更多字段,直到达到最详细的明细表级别的粒度。然而同一个查询不可能包含不同详细粒度,因为详细粒度由维度组合决定,不可改变,比如下面表格的例子:
行:国家 省 城市 列:GDP
这个例子中,详细级别限定在了城市这一级汇总,城市下更细粒度的数据就看不到了,每一条数据都是城市粒度的,我们不可能让查询结果里出现按照国家汇总的 GDP,或者看到更详细粒度的每月 GDP 信息,更不可能让城市粒度的 GDP 与国家粒度 GDP 在一起做计算,算出城市 GDP 在国家中占比。
但是,类似上面例子的需求是很多的,而且很常见,BI 工具必须想出一种解法,因此诞生了 LOD:LOD 就是一种表达式,允许我们在一个查询中描述不同的详细粒度。
从表达式计算来看详细级别
表达式计算必须限定在同样的详细粒度,这是铁律,为什么呢?
试想一下下面两张不同详细粒度的表:
总销售额:
10000
各城市销售额:
北京 3000 上海 7000
如果我们想在各城市销售额中,计算贡献占比,那么就要写出 [各城市销售额] / [总销售额] 的计算公式,但显然这是不可能的,因为前者有两条数据,后者只有一条数据,根本无法计算。
我们能做的一定是数据行数相同,那么无论是 IF ELSE、CASE WHEN,还是加减乘除都可以按照行粒度进行了。
LOD 给了我们跨详细粒度计算的能力,其本质还是将数据详细粒度统一,但我们可以让某列数据来自于一个完全不同详细级别的计算:
城市 销售额 总销售额 北京 3000 10000 上海 7000 10000
如图表,LOD 可以把数据加工成这样,即虽然总销售额与城市详细粒度不同,但还是添加到了每一行的末尾,这样就可以进行计算了。
因此 LOD 可以按照任意详细级别进行计算,将最终产出 “贴合” 到当前查询的详细级别中。
LOD 表达式分为三种能力,分别是 FIXED、INCLUDE、EXCLUDE。
FIXED
{ fixed [省份] : sum([GDP]) }
按照城市这个固定详细粒度,计算每个省份的 DGP,最后合并到当前详细粒度里。
假如现在的查询粒度是省份、城市,那么 LOD 字段的添加逻辑如下图所示:
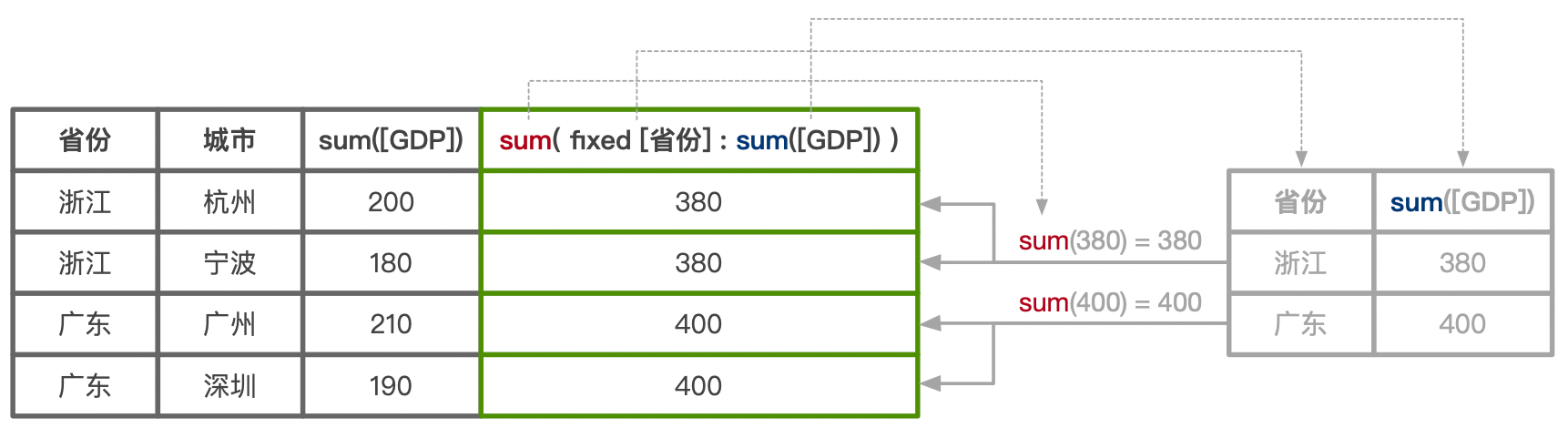
可见,本质是两个不同 sql 查询后 join 的结果,内部的 sum 表示在 FIXED 表达式内的聚合方式,外部的 sum 表示,如果 FIXED 详细级别比当前视图详细级别低,应该如何聚合。在这个例子中,FIXED 详细级别较高,所以 sum 不起作用,换成 avg 效果也相同,因为合并详细级别是,是一对多关系,只有合并时多对一关系才需要聚合。
最外层聚合方式一般在 INCLUDE 表达式中发挥作用。
EXCLUDE
{ exclude [城市] : sum([GDP]) }
在当前查询粒度中,排除城市这个粒度后计算 GDP,最后合并到当前详细粒度中。
假如现在的查询粒度是省份、城市、季节,那么 LOD 字段的添加逻辑如下图所示:
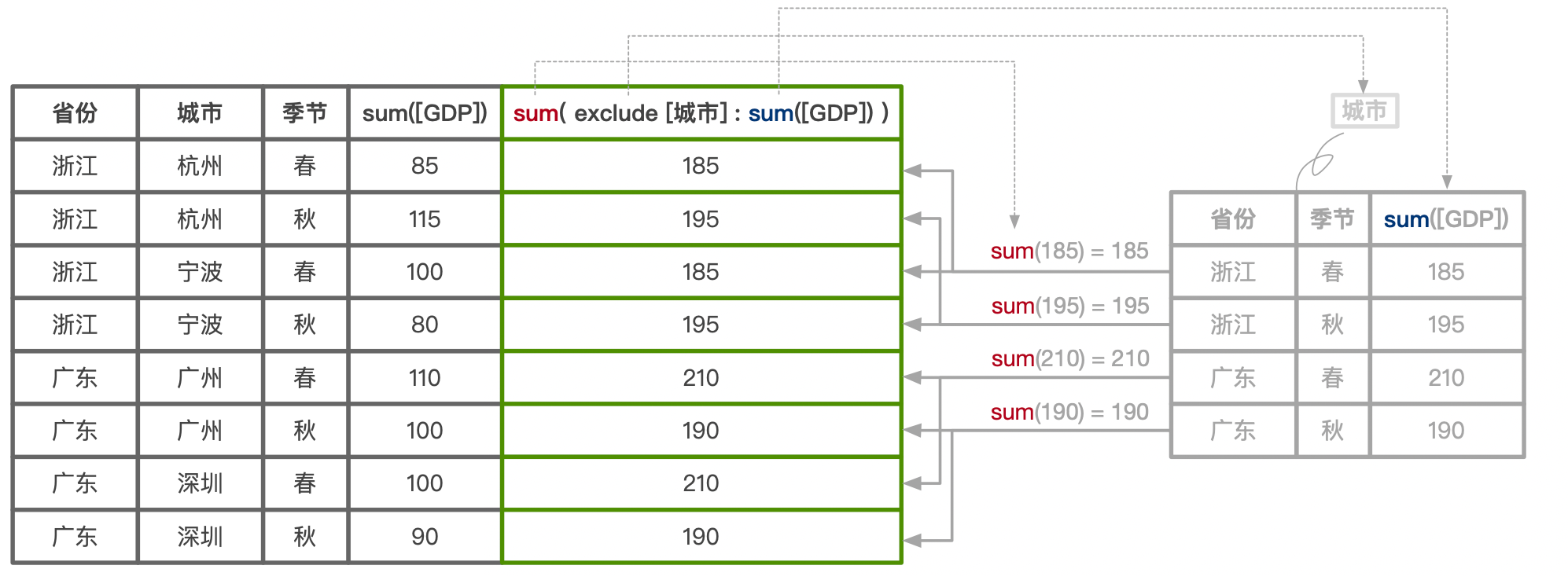
如图所示,EXCLUDE 在当前视图详细级别的基础上,排除一些维度,所得到的详细级别一定会更高。
INCLUDE
{ include [城乡] : avg([GDP]) }
在当前查询粒度中,额外加上城乡这个粒度后计算 GDP,最后合并到当前详细粒度中。
这类的例子比较难理解,且在 sum 情况下一般无实际意义,因为计算结果不会有差异,必须在类似 avg 场景下才有意义,我们还是结合下图来看:
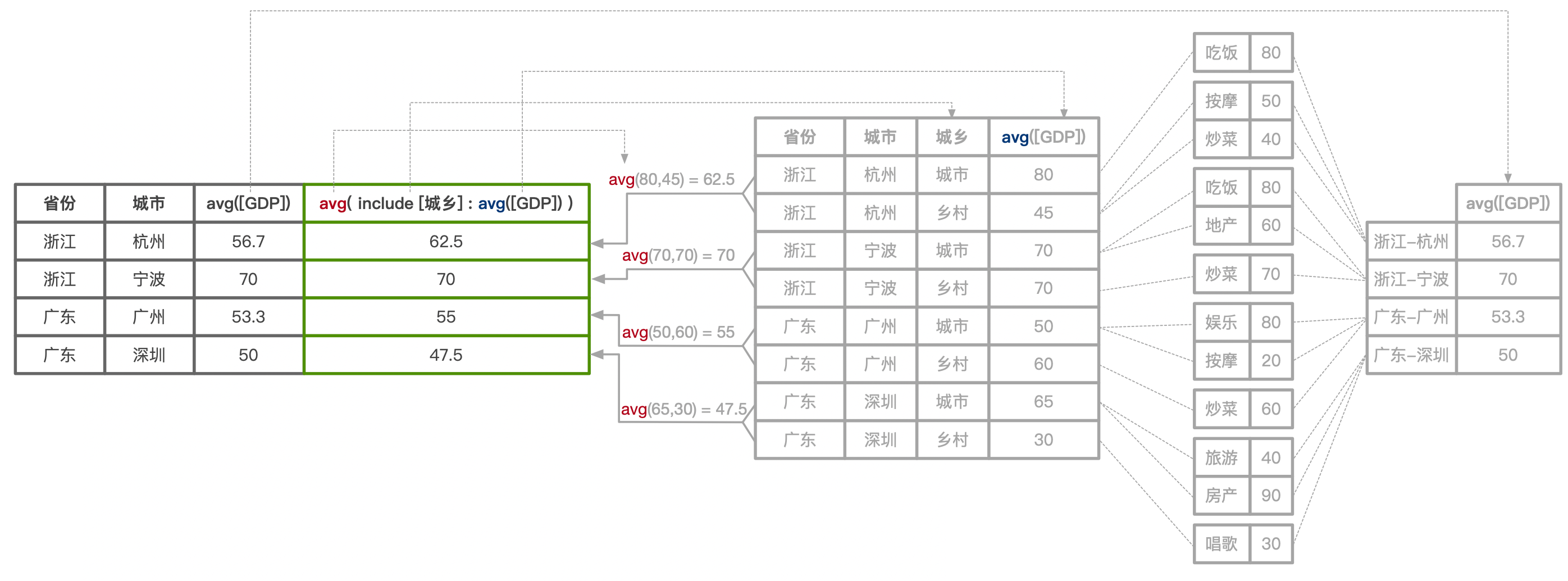
这就是 avg 算不准的问题,即不同详细级别计算的平均值是不同的,但 sum、count 等不会随着详细级别变化而影响计算结果,所以当涉及到 avg 计算时,可以通过 INCLUDE 表达式指定计算的详细级别,以保证数据口径准确性。
LOD 字段怎么用
除了上面的例子中,直接查出来展示给用户外,LOD 字段更常用的是作为中间计算过程,比如计算省份 GDP 占在国内占比。因为 LOD 已经将不同详细粒度计算结果合并到了当前的详细粒度里,所以如下的计算表达式:
sum([GDP]) / sum({ fixed [国家] : sum([GDP]) })
看似是跨详细粒度计算,其实没有,实际计算时还是一行一行来算的,后面的 LOD 表达式只是在逻辑上按照指定的详细粒度计算,但最终会保持与当前视图详细粒度一致,因此可以参与计算。
我们后面会继续解读 tableau 整理的 Top 15 LOD 表达式业务场景,更深入的理解 LOD 表达式。
总结
LOD 表达式让你轻松创建 “脱离” 当前视图详细级别的计算字段。
或许你会疑惑,为什么不主动改变当前视图详细级别来实现同样的效果?比如新增或减少一个维度。
原因是,LOD 往往用于跨详细级别的计算,比如算部分相对总体的占比,计算当条记录是否为用户首单等等,更多的场景会在下次精读中解读。
本文作者:前端小毛
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
