git reflog
reflog 可以看到 HEAD 的移动记录,假如之前误删了一个分支,可以通过 git reflog 看到移动 HEAD 的哈希值

从图中可以看出,HEAD 的最后一次移动行为是 merge 后,接下来分支 new 就被删除了,那么我们可以通过以下命令找回 new 分支
git checkout 37d9aca git checkout -b new
PS:reflog 记录是时效的,只会保存一段时间内的记录。
git stash
stash 用于临时保存工作目录的改动。开发中可能会遇到代码写一半需要切分支打包的问题,如果这时候你不想 commit 的话,就可以使用该命令
git stash
使用该命令可以暂存你的工作目录,后面想恢复工作目录,只需要使用
git stash pop
这样你之前临时保存的代码又回来了
Rebase 合并
该命令可以让和 merge 命令得到的结果基本是一致的。
通常使用 merge 操作将分支上的代码合并到 master 中,分支样子如下所示
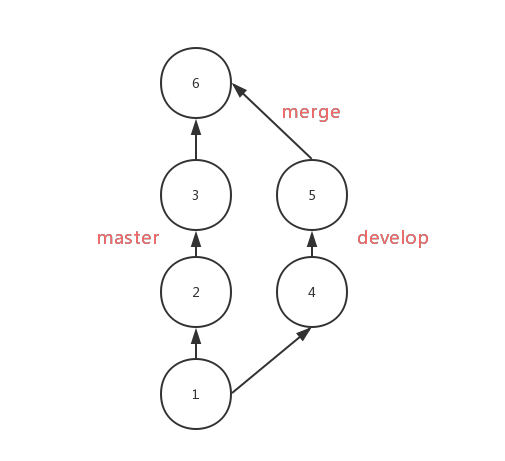
使用 rebase 后,会将 develop 上的 commit 按顺序移到 master 的第三个 commit 后面,分支样子如下所示
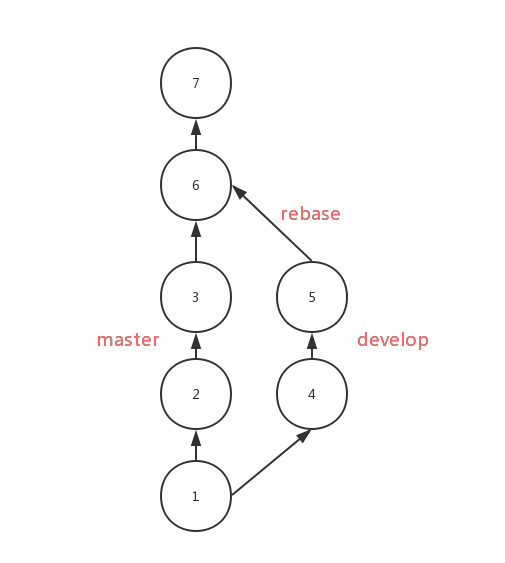
Rebase 对比 merge,优势在于合并后的结果很清晰,只有一条线,劣势在于如果一旦出现冲突,解决冲突很麻烦,可能要解决多个冲突,但是 merge 出现冲突只需要解决一次。
使用 rebase 应该在需要被 rebase 的分支上操作,并且该分支是本地分支。如果 develop 分支需要 rebase 到 master 上去,那么应该如下操作
## branch develop git rebase master git checkout master ## 用于将 `master` 上的 HEAD 移动到最新的 commit git merge develop
从输入 URL 到页面加载完成的过程
这是一个很经典的面试题,在这题中可以将本文讲得内容都串联起来。
- 首先做 DNS 查询,如果这一步做了智能 DNS 解析的话,会提供访问速度最快的 IP 地址回来
- 接下来是 TCP 握手,应用层会下发数据给传输层,这里 TCP 协议会指明两端的端口号,然后下发给网络层。网络层中的 IP 协议会确定 IP 地址,并且指示了数据传输中如何跳转路由器。然后包会再被封装到数据链路层的数据帧结构中,最后就是物理层面的传输了
- TCP 握手结束后会进行 TLS 握手,然后就开始正式的传输数据
- 数据在进入服务端之前,可能还会先经过负责负载均衡的服务器,它的作用就是将请求合理的分发到多台服务器上,这时假设服务端会响应一个 HTML 文件
- 首先浏览器会判断状态码是什么,如果是 200 那就继续解析,如果 400 或 500 的话就会报错,如果 300 的话会进行重定向,这里会有个重定向计数器,避免过多次的重定向,超过次数也会报错
- 浏览器开始解析文件,如果是 gzip 格式的话会先解压一下,然后通过文件的编码格式知道该如何去解码文件
- 文件解码成功后会正式开始渲染流程,先会根据 HTML 构建 DOM 树,有 CSS 的话会去构建 CSSOM 树。如果遇到 script 标签的话,会判断是否存在 async 或者 defer ,前者会并行进行下载并执行 JS,后者会先下载文件,然后等待 HTML 解析完成后顺序执行,如果以上都没有,就会阻塞住渲染流程直到 JS 执行完毕。遇到文件下载的会去下载文件,这里如果使用 HTTP 2.0 协议的话会极大的提高多图的下载效率。
- 初始的 HTML 被完全加载和解析后会触发 DOMContentLoaded 事件
- CSSOM 树和 DOM 树构建完成后会开始生成 Render 树,这一步就是确定页面元素的布局、样式等等诸多方面的东西
- 在生成 Render 树的过程中,浏览器就开始调用 GPU 绘制,合成图层,将内容显示在屏幕上了
DNS 的作用就是通过域名查询到具体的 IP。
因为 IP 存在数字和英文的组合(IPv6),很不利于人类记忆,所以就出现了域名。你可以把域名看成是某个 IP 的别名,DNS 就是去查询这个别名的真正名称是什么。
在 TCP 握手之前就已经进行了 DNS 查询,这个查询是操作系统自己做的。当你在浏览器中想访问 www.google.com 时,会进行一下操作:
- 操作系统会首先在本地缓存中查询
- 没有的话会去系统配置的 DNS 服务器中查询
- 如果这时候还没得话,会直接去 DNS 根服务器查询,这一步查询会找出负责 com 这个一级域名的服务器
- 然后去该服务器查询 google 这个二级域名
- 接下来三级域名的查询其实是我们配置的,你可以给 www 这个域名配置一个 IP,然后还可以给别的三级域名配置一个 IP
以上介绍的是 DNS 迭代查询,还有种是递归查询,区别就是前者是由客户端去做请求,后者是由系统配置的 DNS 服务器做请求,得到结果后将数据返回给客户端。
PS:DNS 是基于 UDP 做的查询。

